|
|
 |
Xssist Blog
|
"White Papers", "Articles" or "Blog", these are the options for the
heading of this section. "White Papers" would be pretentious for Xssist, and would skew
the tone of whatever is written here. Most "White Papers" are formal, and full of marketing.
No "White Papers" here.
"Article" would indicate it is somewhat informative, and hopefully well thought out,
and written.
"Blog" is the unknown, it can range from the absolutely worthless to the utterly shocking, to
the surprisingly brilliant. That seems to be the safest title for this section ;-)
|
Topics to be expected would range from System administration, data centre facilities,
web hosting control panels, virtualization, dedicated server, bandwidth pricing.
|
|
[Sysadmin] Access to servers via mobile device and ssh |
[ More ] |
"Road Warrior", the term for travelers who are armed with all sorts of devices, mainly
electronics, for the road. Things like notebook, gps, mobile phone with gprs and 3G, triband
(GSM 900, 1800, 1900), voltage converters, adaptors for phone jacks, power plugs are all essential,
for travel around the world, and stay online. If you are travelling somewhere remote, you may
need a satellite phone.
Jump to Singapore, and Sysadmins. What are the essentials?
A notebook with 3G would be a good solution for sysadmins who are on call 24/7. However, it
gets a bit tedious to lug around a notebook everywhere. A good alternative is the Nokia 9300i.
Flip it open, and you have a qwerty keyboard. Add in a ssh client and you can access your servers
easily, through GPRS. A bit slow, but good for times when you are offsite, and get called to fix
problems that just needs a restart to a process, or a VPS reboot; things that can be done easily
through shell.
Recommended ssh client for Nokia 9300i: look at mochasoft.dk the ssh client is a demo, but fully
functional. Allows you to test it; pay for license if you like it.
The 9300i keyboard does not have keys like pipe, i.e. | and ` and there is problem with running pico
and pine, and the mochasoft ssh doesn't pass return the way the pico and pine wants it. Mochasoft
allows you to configure "Function Keys" to return characters set by you, in ascii. This can be used
for the absolutely essential pipe character | and the good to have `
The 9300i does not have camera, so that's a plus if you need it for ICT.
If you have ideas or recommendations for devices, for accessing servers remotely, please send it
to us through the contact form. Let's exchange information on how to do our job, i.e. system administration
better.
|
|
[Web hosting] DDOS (Distributed Denial of Service) |
[ More ] |
It is usual for Singapore hosts to disallow services like IRC. This is mainly to avoid DDOS attacks,
which will bring down the provider's network. These attacks can be over 200 Mbps, and will disrupt other
hosts within the same datacentre as well.
The attacker usually controls a large number of bots. These can be PC or servers which are hacked, and
bots are installed. Given the large number of webservers, running php applications, there are a large
number of sites which are vulnerable. Web hosting companies are especially vulnerable, since there are
hundreds of websites on each server, and a customer would just click and install an application, such
as phpBB, and leave it around for years without upgrading.
Such applications would be targeted, and they can be found easily through search engines. How? Just
search for phpbb site:.sg and you would get a large listing of sites. The attacker would use any
vulnerable site found, and install bots, which can be something as simple as a 30 line perl script,
which just listens on a port, and wait for the command to send out udp packets to flood the victim.
What happens to so called dedicated bandwidth then? If a provider gives you a dedicated 2 Mbps connection,
why should the provider be concerned whether or not you host IRC servers? If you get attacked, wouldn't it
be limited to the 2 Mbps? The answer is no. The provider uses a packet shaper or rate limit your connect
to 2 Mbps. However, your provider can not control the amount of traffic going into his connection that
he gets from his upstreams.
Therefore, if a server that has a "dedicated" 2 Mbps connection gets flooded with 200 Mbps of
UDP packets, your provider needs to have more than 200 Mbps to withstand the attack.
In a DDOS on bandwidth, the victim must have more resources than the attacker. As long as the
attacker can gather more bandwidth than the victim, the victim goes down. Since the victim needs
to pay for his bandwidth, it is essentially limited. The attacker can gather "free" bandwidth.
How about firewalls, and appliances which claim to prevent or mitigate DDOS? Installing a firewall
on your own link, which is 2 Mbps or 10 Mbps does not help at all. By the time the traffic reaches your
firewall, it is utilising your bandwidth; and if the traffic is 200 Mbps, your 10 Mbps link is congested.
A firewall at your upstream will help, if your upstream have 1 Gbps, and filters out all the DDOS
traffic, leaving you with your usual traffic. However, your upstream gets additional 200 Mbps of unwanted
traffic.
Essentially, it is a matter of resources. Your upstream can block the traffic, and make it look as
if the attack has stopped, but the upsteam must have resources that is greater than the attack, and must
be willing to do so.
What usually happens is that the Singapore datacentre gives up, and null routes the IP that is attacked;
wait out the attack, usually a few days, and unblock the IP thereafter. This can be disastrous for a
IP used for hundreds of sites, such as on a shared web server.
If you have comments, particularly if you use or represent a Singapore datacentre that can provide protection
against DDOS on bandwidth, please send your comments via the contact form.
|
|
[Sysadmin] RAID 0 scaling on SCSI U320, Bonnie++ 1.93c benchmark results |
[ More ] |
Background: Our partner was planning for the hardware specifications for a search application.
It is disk I/O bound.
Problem: Should they use RAID 0 on 6 SCSI drives, or use their existing
SAN (Storage Area Network) for the storage?
They already have results for the SAN, which
was comparable to results for a single 10K RPM SCSI drive. However, they do not have a server
with 6 SCSI drives to test out. How well does RAID 0 on U320 direct attached storage scale?
We came in the picture, as we have spare servers, and spare storage.
The results are as follows:
No. of Drives
(RAID 0) |
Sequential
Output (Block) K/Sec |
Sequential
Output (Rewrite) K/sec |
Sequential
Input (Block) K/sec |
Random Seeks
/sec |
| 1 | 69110 | 39903 | 84839 | 646.2 |
| 2 | 122336 | 65553 | 155875 | 956 |
| 3 | 143485 | 73467 | 175162 | 1134 |
| 4 | 151223 | 77878 | 174961 | 1273 |
| 5 | 161652 | 81556 | 177173 | 1326 |
| 6 | 168379 | 87636 | 183342 | 1451 |
1 Drive (146GB 10K RPM)
Version 1.93c ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
localhost.locald 4G 240 99 69110 31 39903 15 979 98 84839 19 646.2 12
Latency 37580us 1079ms 1394ms 39491us 18883us 632ms
Version 1.93c ------Sequential Create------ --------Random Create--------
localhost.localdoma -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 2331 95 +++++ +++ +++++ +++ 2569 97 +++++ +++ 9275 92
Latency 33804us 62us 60us 39865us 20us 2635us
1.93c,1.93c,localhost.localdomain,1,1173079504,4G,,240,99,69110,31,39903,15,
979,98,84839,19,646.2,12,16,,,,,2331,95,+++++,+++,+++++,+++,2569,97,+++++,
+++, 9275,92,37580us,1079ms,1394ms,39491us,18883us,632ms,33804us,62us,60us,
39865us, 20us,2635us
2 Drives (146GB 10K RPM) RAID 0
Version 1.93c ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
localhost.locald 4G 234 99 122336 53 65553 26 896 96 155875 36 956.0 20
Latency 37791us 870ms 947ms 94783us 18743us 261ms
Version 1.93c ------Sequential Create------ --------Random Create--------
localhost.localdoma -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 2501 97 +++++ +++ +++++ +++ 2499 97 +++++ +++ 9683 92
Latency 29504us 40us 174us 23272us 20us 2533us
1.93c,1.93c,localhost.localdomain,1,1173092942,4G,,234,99,122336,53,65553,26,
896,96,155875,36,956.0,20,16,,,,,2501,97,+++++,+++,+++++,+++,2499,97,+++++,
+++, 9683,92,37791us,870ms,947ms,94783us,18743us,261ms,29504us,40us,174us,
23272us, 20us,2533us
3 Drives (146GB 10K RPM) RAID 0
Version 1.93c ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
localhost.locald 4G 265 99 143485 59 73467 29 1100 99 175162 40 1134 22
Latency 33781us 1517ms 901ms 16954us 17388us 220ms
Version 1.93c ------Sequential Create------ --------Random Create--------
localhost.localdoma -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 2176 97 +++++ +++ +++++ +++ 2224 98 +++++ +++ 9864 92
Latency 17538us 41us 58us 18929us 45us 2957us
1.93c,1.93c,localhost.localdomain,1,1173092470,4G,,265,99,143485,59,73467,29,
1100,99,175162,40,1134,22,16,,,,,2176,97,+++++,+++,+++++,+++,2224,98,+++++,
+++, 9864,92,33781us,1517ms,901ms,16954us,17388us,220ms,17538us,41us,58us,
18929us, 45us,2957us
4 Drives (146GB 10K RPM) RAID 0
Version 1.93c ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
localhost.locald 4G 242 99 151223 64 77878 32 991 96 174961 41 1273 28
Latency 36060us 868ms 1010ms 94718us 25317us 401ms
Version 1.93c ------Sequential Create------ --------Random Create--------
localhost.localdoma -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 2243 97 +++++ +++ +++++ +++ 2423 97 +++++ +++ 9872 93
Latency 15938us 45us 54us 26997us 21us 2859us
1.93c,1.93c,localhost.localdomain,1,1173094078,4G,,242,99,151223,64,77878,32,
991,96,174961,41,1273,28,16,,,,,2243,97,+++++,+++,+++++,+++,2423,97,+++++,
+++, 9872,93,36060us,868ms,1010ms,94718us,25317us,401ms,15938us,45us,54us,
26997us, 21us,2859us
5 Drives (146GB 10K RPM) RAID 0
Version 1.93c ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
localhost.locald 4G 247 99 161652 69 81556 34 1008 99 177173 42 1326 28
Latency 36168us 865ms 945ms 20790us 24184us 487ms
Version 1.93c ------Sequential Create------ --------Random Create--------
localhost.localdoma -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 2343 97 +++++ +++ +++++ +++ 2207 98 +++++ +++ 9306 93
Latency 18566us 36us 52us 16534us 32us 2687us
1.93c,1.93c,localhost.localdomain,1,1173093546,4G,,247,99,161652,69,81556,34,
1008,99,177173,42,1326,28,16,,,,,2343,97,+++++,+++,+++++,+++,2207,98,+++++,
+++, 9306,93,36168us,865ms,945ms,20790us,24184us,487ms,18566us,36us,52us,
16534us, 32us,2687us
6 Drives (146GB 10K RPM) RAID 0
Version 1.93c ------Sequential Output------ --Sequential Input- --Random-
Concurrency 1 -Per Chr- --Block-- -Rewrite- -Per Chr- --Block-- --Seeks--
Machine Size K/sec %CP K/sec %CP K/sec %CP K/sec %CP K/sec %CP /sec %CP
localhost.locald 4G 248 99 168379 72 87636 35 969 96 183342 44 1451 31
Latency 33562us 912ms 1374ms 102ms 14077us 254ms
Version 1.93c ------Sequential Create------ --------Random Create--------
localhost.localdoma -Create-- --Read--- -Delete-- -Create-- --Read--- -Delete--
files /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP /sec %CP
16 2500 98 +++++ +++ +++++ +++ 2271 99 +++++ +++ 10091 97
Latency 10374us 43us 60us 12506us 20us 303us
1.93c,1.93c,localhost.localdomain,1,1173114597,4G,,248,99,168379,72,87636,35,
969,96,183342,44,1451,31,16,,,,,2500,98,+++++,+++,+++++,+++,2271,99,+++++,
+++, 10091,97,33562us,912ms,1374ms,102ms,14077us,254ms,10374us,43us,60us,
12506us, 20us,303us
|
|
[Web hosting] Uptime for dedicated server, VPS and shared server |
[ More ] |
It is true. Dedicated servers for single sites in general have better uptime compared
to VPS, and VPS has better uptime than shared server.
The observation is as follows:
For shared servers, many sites are located on 1 physical server. All these sites compete for
cpu, disk and bandwidth, and each site can be a backdoor to the server. There is usually no
control over how each account uses the server resources, except where disk or bandwidth quotas
are exceeded. Control panels for web hosting do not have CPU quotas; i.e. limiting cpu
usage based on userid, or per process. There are so many applications installed, and of
various versions. Don't expect the users to update their applications. Therefore, when a
security hole is found, it is easy to gain access to several accounts on a shared server;
usually through a php application, such as phpbb or phpnuke. With access to php on the
accounts, the intruder (or "hacker") has as much access as if he has shell.
Through this access, he can gain root privileges if the kernel is not up to date, or even
if it is. Well, or he can just buy an account on the server. The motivation however, is
usually to gain free usage of the server, to run psybnc, eggdrop, or scripts to scan
other servers, or udp.pl to udp flood their victims. The side effect is that some of
these scripts take up 100% of the cpu, and leaves the other accounts starved of CPU.
Or with the udp flooding, the server gets starved of bandwidth. Either way, the shared
server gets starved of resources, and just can't keep up with legitimate requests to serve
webpages. The server may be up, the network may be up, but your website is so slow, as
to be unusable. Other consequences may be mass defacement, or malicious rm -rf of the
entire server.
VPS, eg Virtuozzo, fares better, in the sense that each VPS has its own "contained"
environment. Each VPS can be configured to have its own guaranteed bandwidth and CPU shares.
The common bottleneck for VPS is disk I/O. Any VPS can use up the bulk of the disk I/O on a physical
server. Vitualisation software needs to come with a means to control disk I/O allocation. This
does not seem to be available currently. It can be controlled by giving each VPS its own
dedicated harddisk; however the bus, whether SCSI or PCI, can still be hogged by a single VPS.
Another issue which affects uptime for VPS involves SCSI. A failing disk for any VPS can bring
down the physical server. The MPT (LSI Logic) driver does not seem to be able to recover from
some SCSI errors, eg. "mptbase: ioc1: IOCStatus(0x004b): SCSI IOC Terminated",
the driver will try a "task abort!", but server just hangs. The physical server for
VPSes tend to be worked hard, from the CPU to the storage; and both hardware and software are
not prefect. Servers that get worked hard tend to hit the bugs, and crash, leading to relatively
lower uptime compared to dedicated servers. One advantage for Virtuozzo VPS: it is very easy to
migrate the VPS from one physical server to another. Virtuozzo uses rsync to do the transfer; rsync
the contents, shutdown the original VPS, rsync again to bring the new VPS up to date, bring up the
new VPS.
Hosting on dedicated servers, given the reasons above, would have the best uptime. i.e. no other
website or VPS to compete for resources. No other website which introduces security problems.
Lower load on the CPU and storage of a dedicated server. Of course, this is vs hosting
the same website on shared, or VPS. The dedicated server would still need to be of good quality.
We are comparing like vs like; same quality of hardware. I will cover the types of dedicated servers
that are offered by webhosting companies in another piece.
Lim Wee Cheong
11 March 2007
|
|
[Web hosting] Shared, Guaranteed and Dedicated Bandwidth |
[ More ] |
Shared bandwidth
The hosting provider subscribe to a certain amount of bandwidth from the ISPs, eg. 5 Mbps,
and all clients shares that 5 Mbps. When the 5 Mbps gets congested, and the clients get very
slow accesses, the hosting provider may or may not upgrade the bandwidth. If your usage is
excessive, as determined by the provider, your usage is likely to be capped.
Guaranteed bandwidth
Almost all bandwidth on the Internet is shared. However, providers can provide higher priority
to the bandwidth for customers who pays for a higher SLA (Service Level Agreement). This is the
meaning of "guaranteed" in guaranteed bandwidth.
The gold standard in providing bandwidth management is to use Allot Netforcer or Packeteer.
These cost up to SGD 30,000 for 100Mbps shaping, to provide QoS (Quality of Service) guarantees
to each client. There will still be a shared pool of bandwidth, eg. 45 Mbps. Out of this 45 Mbps,
there may be 100 servers. Depending on the bandwidth subscribed by these clients, the hosting
provider can set guaranteed bandwidth, burstable bandwidth, and priority to the bandwidth.
Some providers use DIY bandwidth management, using freebsd.
Some high end application switches, and firewalls also provide bandwidth management;
where there is a setting for guaranteed and burstable bandwidth.
Lower cost providers will use rate limit per port on their switches to provide "guaranteed"
bandwidth. They limit your bandwidth to a certain amount, eg. 2 Mbps, and what you actually get is
zero guaranteed bandwidth, burstable up to 2 Mbps.
Dedicated bandwidth
There is no true dedicated bandwidth on a Internet wide basis.
Analogy (bandwidth to roads)
Bandwidth subscribed by your provider = size and condition of the road
Clients = vehicles on the road
- Shared - everyone gets to use the road. cars, lorries, buses. If you hog the road, the
Traffic Police stops you. If you hog too often, you will get punished.
- Guaranteed - Bus Lanes, or Motorcade escorted by traffic police, or Parades
- Dedicated - No other vehicle can use the road, even when you are not using it.
example, drive any where within Singapore, and there is no traffic lights, no other vehicle on
the road, any time of the day.
Wee Cheong
11 Apr 2007
|
|
[Sysadmin] TODO (Apr 2007) |
[ More ] |
1. URL blocking to deter phishing
We have been getting more and more cases of phishing sites being hosted on clients accounts. PHP scripts,
particularly popular scripts for forums, CMS and blogs which are not brought up to date, are pretty vulnerable
to attacks. Attackers will place their files into the cracked accounts. The most commonly phished sites are
banks, ebay and paypal.
Since we do not have access to many of the servers, being unmanaged, and really do not want to mess with clients'
scripts on shared servers; a solution would be to block all incoming requests for URLs with bankofamerica, paypal
and ebay in the URL. Need to monitor existing requests to ensure there's no legitimate pages having these
keywords. Probably do a redirect to a webpage with info, so users can contact us if their pages get blocked.
2. Spam mails
Another bane of web hosting is spam mails. Most antispam require installation on servers, or if they are
appliances, would require a proxy smtp setup.
A transparent antispam appliance would be nice, both for incoming and outgoing connections; and would not
require customers to change configuration. Servers would still have antispam such as spam assassin. This
would be an addition, and also prevent cracked accounts from sending out spam from our servers.
3. Nagios
Look into monitoring of servers using Nagios. Use together with a GSM modem to send out SMS when services are down.
4. NTOP and Colasoft
Used to have NTOP running, but NTOP crashes every few days. Need to try it again, to have statistics in
addition to what we have currently. Check Colasoft products as well. For statistics, more is usually better ;)
5. Packeteer (Packet Shaping)
Just got a Packeteer with 100Mbps shaping. Will need to set this up, in addition to the Allot Netenforcer 45Mbps we
have currently. Will be able to provide customers with a login page, with monitoring of their bandwidth usage.
30 Apr 2007
|
|
[Sysadmin] Recover from mistakes in /etc/fstab or e2label usage |
[ More ] |
Server hanged. Called up datacentre to reboot, and it never came up. That is a dreadful scenario.
One of the worst problem is to have a faulty harddisk.
What I would like to cover here though, is human errors, eg. the case where /etc/fstab is misconfigured.
I have clients who changed /etc/fstab, do mount -a and see no problems. Later on, probably weeks or months
later, the server does not come up after reboot. On the console, we would see error messages like the following
fsck.ext3: Unable to resolve 'LABEL=/boot'
fsck.ext3: Unable to resolve 'LABEL=/home'
*** An error occurred during the file system check.
*** Dropping you to a shell; the system will reboot
*** when you leave the shell.
Give root password for maintenance
Or you have a server that has hardware failure, other than the disk, and you want to mount the disk in
another server, only to find that both disks have the same paritions! eg. / /boot /usr etc and the
server refuses to boot.
ok, so you enter in the root password. What next?
A few useful commands here; just in brief, enough as keywords for you to go googling for details,
or check the man pages.
| fdisk -l | (to find out the partitions on the disks) |
| e2label /dev/sda1 | (find out or write the label for a partition. in this case,
partition 1 of /dev/sda. of course, IDE disks will show as /dev/hda etc) |
| mount -o remount,rw / | (remount a readonly filesystem readwrite so changes
can be made, especially to files like /etc/shadow, /etc/fstab, /boot/grub/menu.lst etc) |
| passwd | (change the root password if you have forgotten) |
Sometimes it is useful to go into single user mode, especially if the server hangs when it tries
to bring up the network. To do so, when grub comes up, press the up or down arrow keys, select one of the
kernel, press 'e' for edit, and append "single" to the end of the line. come out of the editing
by pressing enter, and press 'b' for boot. Also useful when you have SCSI RAID drivers, other than provided
on the installation disk, on the server. So you really want the server to boot up with the drivers.
Usually, if you have access to the console, it is easy to boot up using CD. example, the server cd of centos.
key in linux rescue at the prompt, and you will get a nice environment to use for fixing your server.
|
|
[SPAM handling] Tracking applications which are exploited for mass spam mailing |
[ More ] |
It can be difficult to trace which account, and which application is being exploited for mass spam mailing.
Especially so for shared servers which are used by hundreds of websites, and running php as an apache module. The
user which is sending out the spam will be the user running the apache process, i.e. "nobody.
Interestingly, mod_security can be used here. Enable audit for mod_security with the following lines:
SecAuditLog /usr/local/apache/logs/audit.log
SecAuditEngine ON
also add the following:
SecFilterScanPOST On
SecFilterSelective "POST_PAYLOAD" "put unique string from offending mail here eg. LOTTERY"
and you can check /usr/local/apache/logs/audit.log for which URL is being posted to, and the content of the POST.
From there, you can decide to suspend the account, disable the application, put the URL into your firewall etc.
and here's a few exim command lines for managing your mail queues:
exim -bp # lists out the mail queue
exim -Mvl <msgid> # shows log for the particular message
exim -Mvb <msgid> # view body of message
exim -Mvh <msgid> # view header of message
exim -Mrm <msgid> # removes message from queue
Lim Wee Cheong
27 May 2007
|
|
[Web hosting] Unmetered bandwidth |
[ More ] |
One of the ploys used by web hosting companies is to offer unmetered bandwidth.
Unfortunately, bandwidth is the most expensive component of most web hosting companies in Singapore. Is it
possible to offer something that costs money for free? Yes, if customers do not use alot of bandwidth, and
pays up sufficiently for disk or other components of a web hosting plan.
Market price for 1 Mbps is around SGD 250/mth. That translates into just 100GB/mth based on experience; particularly
for small web hosts with only 1 Mbps bandwidth. Guess what? Just 1 website, usually forum site or photo hosting,
can take up the entire 100GB/mth. Is it then profitable to charge $5/mth for unmetered bandwidth? No. So
what happens when you purchase one of those $5/mth unmetered bandwidth accounts, and end up using 100GB/mth?
You have a good chance of getting your account suspended, and getting your usage capped.
Based on experience, having access to statistics of over 5000 websites. The majority of websites, i.e. over 90%,
uses less than 1GB/mth. Just pay for what you really use, and your webhost is more likely to be able to
support your site, and they are more likely to stay around.
If you still want to get plans with unmetered bandwidth, take a good look at the terms and conditions of the plan.
The following are just some of the terms I have seen for unmetered plans: No forum site. No photo hosting.
Cannot provide downloads of files. Cannot provide chatting. Cannot take up too much CPU resource.
Put it this way: think of something you use regularly every month. Let's say petrol. If someone offers you
unmetered petrol for $50/mth; pump whenever you like. Pay $600 for 1 year upfront. Would you take up the offer?
Lim Wee Cheong
28 May 2007
|
|
[Web hosting] Free domains? |
[ More ] |
Would you like a free domain to go with your web hosting plan?
That is an offer that is rather common. Domain registrations cost the web hosting provider money. So the
cost needs to be passed on to you in some way, usually the cost is added to the plan that is offered to you. Are
free domains really free?
Your domain name can be very valuable. Search engines recognise your site based on the domain name. Your customers
or users can reach you using your domain name. Emails get to you because of your domain name. It costs only
SGD 20/yr or less. You can always switch web hosting providers, because your domain name can be pointed to different
IPs. This can be the single most important item for your website. Not a reliable web host, not a good server,
not good uptime; the single most important item is the rights and control over your own domain name.
There are at least 2 web hosts in Singapore which provides "free" domains, and when customers want to switch
to another provider due to poor service, they get a bill of several hundred SGD, usually close to SGD 500 to get
the domain name back, because the "free" domain is registered in the web hosting provider's name, and
"owned" by the web hosting provider.
Always register your domain name yourself, unless you trust your web host absolutely. Never allow your employee
to register the domain name in his name. Always check the registrant and registrant email is in the company's name.
Remember, your domain name is very important. Some domains can sell for significant amounts, and if your domain has
significant traffic, and drives sales for you, the value is many many times more than a SGD 20/yr registration fee.
Lim Wee Cheong
30 May 2007
|
|
[Sysadmin] Server overloaded? |
[ More ] |
One of the favourite datum that sysadmins and users alike use for accusing server of being overloaded is... 'uptime'
Oh no! load is 100+, server is dying. What do you do next, or how do you find out what's actually causing the load to be 100+ ?
First, we need to understand what 'uptime' is telling us. The man pages would be the first place to look right? man uptime. It says system load
averages for the past 1, 5, and 15 minutes. errr. What does that mean? Ok.. without pointing to authoritative sources, let me state that the
figure actually means the average number of active, running processes. Just take it as that for the time being ;)
Next, let us consider what figures are actually a cause for concern. Now, the load figures are just the average number of active running processes
over a period of time. You could have hundreds of processes that took up slices of CPU, but on average, let's say the load figure is 5.. that means
at any time, 5 processes need attention from the CPU.
Would a load figure of 8 be a high figure? Yes, it might, if you have 1 CPU core, which means on average, 8 processes want to use the 1 CPU. BUT
if you have 8 CPU cores, the server is running fine... usually. Why do I say a load of 8 on a 1 CPU core server MIGHT be high, rather than it
DEFINITELY is high? The catch here is that the processes might not be CPU bound, they might be waiting for disk IO. But let's leave that for later.
Why does the number of active processes sometimes chalk up into the hundreds?
The usual suspects?
1. runaway process (CPU starved, or CPU bound)
2. run out of RAM, and processes getting swapped to disk (RAM starved or RAM bound)
3. heavy disk IO, leading to processes waiting for disk IO to complete (Disk IO starved or Disk IO bound)
The unexpected...
4. server is starved for network bandwidth. Network bandwidth bound.
Each of the above is a topic on its own. I'll stop here for this entry. If you want to find out more on your own, check out iostat, dstat, top,
vmstat, free and iftop.
Suffice for now to say that the load figures from 'uptime' or 'top' just displays a symptom.. it shows there's a bottleneck that is delaying
processes from completing its run. It doesn't say the CPU is too slow.. which is what most users think it means. and that's a wrong diagnosis lots
of time.
Lim Wee Cheong
Sysadmin
30 Dec 2007
|
|
[Sysadmin] Server load high: CPU bound |
[ More ] |
When server is unresponsive, slow, etc, one of the first reactions is to run 'uptime' or 'top'. Most users, and unfortunately, many sysadmins stop
there and make the conclusion that the CPU is too slow. Lots of time, in a webhosting environment with control panels, logging, and statistics
generation such as awstats, analog, and webanalyzer running, the fault lies in insufficient disk IO. However, sometimes we do see CPU being the
bottleneck. How do we know the CPU really is working like mad, and its not waiting for disk IO to complete? Simple, run 'top' or 'iostat' and check
the iowait. It should not remain high. How high is high? That is left as an exercise. There are several common scenarios in webhosting and
dedicated servers with cPanel, where CPU usage gets high, and the applications do not take the attention they need, and affects the user's
experience.
1. Runaway processes
Sometimes, user applications are buggy, and just keep running. Something as simple as while (1){}; if the web site gets just a few hits a second,
the server will crawl real soon. Pretty soon, the server goes into a death spiral. First, the CPU runs flat out, then the processes adds up, and
there are more and more httpd and php processes which takes up more and more RAM. RAM gets used up, processes starts to swap out to disk; and it
goes further down hill from there.
One really cute scenario I encountered along these lines; the user application calls itself. Something like "curl http://usersite/a.php" in
a.php itself.
Of course, its possible to limit the number of processes owned by the user, and to limit the total number of httpd processes, amount of memory
taken, CPU time etc. Out of scope of this entry though. Only trying to describe CPU bound processes in this entry, so I will just list out
keywords that will help if you need to look further: ulimit, /etc/security/limits.conf, httpd.conf
Just chmod 000 those user accounts that are running crazy, and kill -9 the processes. Also crontab -l -u userid to see if there's any cronjobs
running.
If you are in a new job, just took over a server and there are processes running which you can't find in /etc/init.d, check /etc/cron.* these are
all CentOS paths and filenames.. YMMV, if you are using other favours, that's why we try to stick to one favour of linux (and unix) as far as
possible. If you have freebsd, redhat, debian, solaris, tru64, aix etc in one shop.. good for your resume, not too good for your sanity :)
2. Deliberate hacking attempt
Many web applications are unfortunately buggy and easily exploited with exploit scripts distributed around. Shared web servers are easily hacked
in some way or other. The guys who hack the site then runs scripts which keep their irc processes alive, port scan, or send out UDP floods. Alot of
these scripts are very buggy, worst than the web applications, and they tend to take up 100% of CPU. This makes them easily detected when they
show up on 'top'. A few things need to be done; trace which application is vulnerable (modsecurity can be very helpful here, with auditing enabled),
disable perl for the nobody user, eg. using setfacl (unfortunately, this breaks some cPanel functions), setup iptables to disallow outgoing traffic
to unknown ports, and especially UDP if not required. Again, lots of topics here which is out of scope.
3. Normal processes such as mysql or apache just taking longer and longer to complete as your sites get busier.
my.cnf, the mysql config file, as it comes with cPanel is not good for busy sites. If you run mysqladmin status and see lots of slow queries, you
run mysqladmin processlist and see lots of queries that's taking more than 1 second or so to complete, its time to check into my.cnf and see if you
can tweak it a bit, usually give it lots of cache. Google for my.cnf optmizations and you should have lots of hits. Also check that your
databases are properly indexed. How about apache? a really good thing to do there is eaccelerator.
4. Application upgrade goes wrong
An application such as moodle can go from working smoothly to taking up all your CPU, from one version to another.. due to upgrades going wrong,
usually due to differences in the database tables. if you can, its really best to do a brand new installation, and do a migration, rather than
upgrade in place.
Lim Wee Cheong
01 Jan 2008
|
|
[Sysadmin] Smokeping: deluxe latency measurement tool |
[ More ] |
Smokepine is a very nice tool to have. We run ours on http://www.xssist.com/smokeping/
and it is publicly accessible. We want customers to know what they are paying for. A ping of 30ms during off peak
may be 200ms during peak to your particular location.
Web hosting companies have been offering uptime of 99.95%, regardless of size, regardless of infrastructure. Wow, anyone can offer great uptimes,
the Internet must be really reliable, right? Not really. The Internet is a best effort network. Google for smokeping targets, and look at the charts
available. Particularly for the 400 day chart, there's seldom solid, straight green lines.
How to interpret the graphs? Firstly, the host that the smokeping binary runs on does affect the results. We run smokeping on a pretty busy VPS.
There are times where there's lots of backup activity going on, lots of disk IO, and lots of bandwidth usage, and that shows up as spikes just
after midnight. Likewise, the choice of targets matters. Some of the targets are websites, and they do go down once in a while. Other targets
like routers give very low priority to ICMP, which is the right thing to do, especially when swamped with traffic, and the packets come back alot
slower than usual, although other traffic may not be affected. ping is a pretty good indicator of the health of the network otherwise.
One of the things that smokeping has caught is our main firewall slowing down packets. The firewall was configured to send out syslog messages, and
the CPU simply could not cope, and ended up slowing packets and dropping around 3%. It has also been very good in cases where customers from
specific countries report problems with the network. We can check back on SmokePing, and see if there's packet loss, and high latency during the
period reported.
01 Jan 2008
|
|
[Buzzwords] Clusters, Clustering |
[ More ] |
It looks like "unmetered", or "unlimited", or 99.999% uptime is no longer the buzz word in web hosting. The buzzword now is clusters.
If you look for details, they are no where to be seen. Clusters, what are they? Web hosting companies would have you believe clusters
are so much more reliable than a single shared server, or even your own dedicated server. Is this so? "Clusters" by itself really have
no meaning, it describes nothing or it means so many things that it really needs an explanation to make any sense.
Questions: What exactly is being clustered? How does it work, what does it do?
Chances are, the web hosting company have no idea other than its a buzzword to use in their advertising. To choose a good hosting
provider, you need to separate the wheat from the chaff. To do that, you need to understand the basics.. clustering is the end
solution to a problem. The problem is HA (High Availability), or how to achieve HA. Let's start with a single server. How do you
reduce downtime, i.e. have it available more, or to have higher availability? There are many ways for the server to fail. For each
failure that can cause the server to go down, we call it a Single Point of Failure or SPOF. There are very obvious SPOFs in a single
server. They are as follows:
- Power supply
- Harddisk
- RAM
- Human (System administrator, programmers, users)
For power supplies, chances of failure can be reduced by having redundant power supplies. It is a misnomer of course. The
redundant power supply is not really redundant, it is there so that if a power supply fails, the spare will continue to supply power
to the server. Of course, if you are able to power dual sourced power to the power supplies, i.e. one power utility powers one of
the power supply, another utility powers another power supply etc; and add to it, UPS, and generators, that will cover most
of the problems the power might face. There's still the power train, but less likely to fail. Also a leakage to earth might trip a
circuit breaker etc. In any case, an enterprise server must have redundant power supplies.
Harddisk. Easily the most crucial part of the server. Any other part can be replaced without losing data. Lose the harddisk, and we
might lose data. RAID comes in here. Usually RAID 1, which is mirroring. For RAID, higher numbers does not mean better. In particular,
RAID 5 is largely useless for web hosting for busy websites, as RAID 5 implementations usually performs very badly when there are
multiple reads and writes. For servers spec-ed for enterprise, you need multiple storage cards connecting to multiple storage, which
are mirrored, such that the storage card, i.e. the host bus adaptor (HBA) does not become the SPOF.
RAM for servers need ECC at a minimum, and goes on to RAID 1, and further on to hotswappable for the truly highend.
The human, otherwise known as the system operator, or sysadmin, or programmer etc etc, is unfortunately, one of the weakess link.
This is the person who goes rm -rf / ohhh.. opps. OR trips over a power cable OR pulls out the wrong harddisk out of a RAID array.
Training and experience is important here.
After all of the above is covered, and if the availability is insufficient, we can start thinking about clustering in the sense of
having a duplicate server; i.e. a passive - active cluster configuration. For most of everything you have above, duplicate them, and
have the equipment sitting around (passive) doing nothing except take over when your active server dies. How does the passive server
(otherwise known as node) know to become active? Heartbeat comes in here. This can be in the form of a cross cable between the two
nodes. Software on both nodes tries to communicate with each other, and if the communication gets cut off, the passive node tries to
become active.. However, the heartbeat link can be a SPOF.. so duplicate that, and we have 2 heartbeat links.. oh, and if possible,
please get separate NIC (network interface card) for each of the link. Then we run into the problem of storage. How to ensure the
passive node has updated information? A shared storage comes into the picture, where each node have access to a shared storage.
Then we run into the problem of ensuring the active node is not still accessing the storage, i.e. it is actually dead, and the
passive node can take over the storage...
It goes on and on, and along the way, SAN (storage area network) gets introduced, or perhaps drbd for the DIY poor man version of
clustering.
When do you failover a node? if you have mail, dns, web, pop, imap etc on a server, does your software try restarting the individual
daemons, how many times does it try before failing over the node? does 1 failed service justify failing over the node? after failing
over, how do you fail back ? or do you have 1 mail cluster, 1 web cluster, 1 pop cluster etc? how do you share storage?
The point is, most webhosting companies which does not explain what their clustering is doing, is just doing a poor man version
without a good background, with cheap servers, without reducing the SPOF which should be fixed within the sever, and is a worse
risk than if they provide you with shared or a single server. imagine: use NFS for mail spool? that's what some of these guys will
try.
Clustering.. is a double edged sword. Do it well, and it just might work.. do it less than perfect, and you are at the brink of
disaster.. everything looks great, and one day it just goes poof. where possible, keep things simple.
07 Feb 2008
|
|
[Web hosting] Joomla Scalability |
[ More ] |
One of our client website uses Joomla. The site gained quickly in popularity, and bandwidth usage grew rapidly. We added more servers and
bandwidth for the customer, as far as we can, limited by his budget. Eventually, the site hit a bottleneck in how Joomla uses the mysql
database. There were just too many updates, and queries going on, and with updates locking the database, the site will slow down to a crawl.
Surprisingly, changing the table from myisam to innodb didn't help; the idea being innodb wouldn't lock the table. Eventually, we
identified the event that triggers the site to slow down. Interestingly, adding new articles causes as many updates as there are articles
in the database table. If there are 5000 articles, there are 5000 updates. Why would adding 1 article cause 5000 updates. Looking at the
code, I found the cause to be the way articles are sorted in Joomla.
updateOrder in database.php has a for loop which goes through each record to be reordered and adds 1 to the ordering.
This was for Joomla 1.0.x; Hopefully, 1.5.x does it differently.
I couldn't find mention of this using google; so hopefully this entry can help someone else having the problem.
One workaround would be to disable the ordering, and use order by date in the frontpage display, rather than order by sorting.
Lim Wee Cheong
08 Jun 2008
|
|
[Sysadmin] Smokeping |
[ More ] |
Smokeping, which does ping periodically, and graphs the results, have been invaluable. Here's the link to our smokeping page:
http://www.xssist.com/smokeping/
When we first started using smokeping, some of the results were totally off. The graphs were recording high latency for pings to the firewall
periodically, when we were expecting under 1ms. Turns out, having syslog on for our firewall was overloading the CPU.
We added more locations over time, eg. Hong Kong, Indonesia, Malaysia, Vietnam, USA, UK. When there's problems, we feedback to our datacentre
provider, and the network guys has been responsive to fixing problems.
How to interpret the graphs? Why does some of the graphs show alot of deviation?
There's a bit of trial and error to the targets that we use for the graphs. Some of the targets are servers, some of them are routers. Many
routers will slow down responses to ICMP packets when the CPU is busy, and that is shown as higher latency in the graphs although normal
traffic is not affected. Sometimes the servers choosen has low bandwidth, and the latency shoots up during peak usage.
As far as possible, we try not to use these (busy routers, bandwidth starved servers) as targets.
Why do we want to show customers these graphs when some of them look downright ugly?
1. "Debugging". Can you think of times when you encounter problems with the network, send an email to your service provider, and they respond
later that there's no problems ? We need to keep a record so when customers tell us there's problems at a particular time, we can get our
provider to check, and provide them with the graphs to help them check. This reduces the time taken to resolve problems. Also, we check
the graphs periodically, if we notice problems, we get our provider to fix them. What we have not yet done but would like to, is to do
active monitoring with thresholds, and SMS alerts when those thresholds are breached.
2. Customer expectations and customer turn over. Our target market are sysadmins, people who understands the Internet is a best effort network,
who chooses to pay more for SCSI, and brings around a UMPC with 3G. We do not mind scaring away potential customers who expect a perfect
network with 0% packet loss 24x7 to all locations around the world; customers who ask why ping round trip from Singapore to USA latency
is 200ms and not 30ms. We also want customers to know what they are paying for, and if the network is not good enough, they should know
beforehand, and not after paying.
Xssist
08 Jun 08
|
|
[Sysadmin] Jul 08 to Oct 08 updates |
[ More ] |
We have been busy for the past few months provisioning servers for clients. We have added ~30 servers, including several 8 CPU cores, 32GB
RAM, RAID 10 servers. These are excellent as database servers. We continued to have good results with our dual socket dual core web servers
as well.
Increasingly, clients are asking for internal gigabit networks, private VLANs, for internal traffic such as mysql and NFS. We have been adding
more gigabit switches to meet these requirements.
We are looking at retiring or upgrading older servers. As of end Oct 08, we have retired ~20 servers which are dual socket single core.
The retired servers are in storage currently. Ideally, we would like to donate the retired servers to education, non profit or charity
organisations within Singapore. These servers are heavy, around 20KG each, so shipping out of Singapore may not be cost effective.
The servers are rackmountable 1U servers, very high speed fans, so they are very noisy. If you know of individuals or organisations
who can make good use of these servers, please contact us.
Xssist
20 Nov 08
|
|
[Sysadmin] Weak link - downtimes caused by the organic being |
[ More ] |
A chain is only as strong as its weakest link. On 2 separate occasions in the past 2 months, the sysadmin proves to be the weakest link.
Similar problem in each case, faulty RAM in the server. We had to replace the RAM. Unfortunately, tracing 1 faulty RAM module out of
several.. eg. 16 modules in a 32GB server with 2GB modules can be more difficult than it seems. The OS might indicate which CPU and which
slot has the ECC error. The server might has a fault panel that points out the DIMM slot. However, sometimes we just have to swap modules
in and out.. and each time having to plug out the power cord, KVM cables, network cable, SCSI cables, etc, pull out the server on its
rails, open the casing, swap the RAM, put everything back and power on the server. If it works, good, if not, repeat all of the above.
On one occasion, during booting, error messages start coming up from the SCSI card.. oops. SCSI cable not connected.. sysadmin starts
panicing.. what if the configuration gets corrupted? quick, pull out power cable.... hmmm... screen continues scrolling.. OOPs.
pulled out power cable of another server.
On a separate occasion, need to replace RAM in a server, and install a APC fan, ACF002, for the rack to improve air flow. Pushed the fan
module too far back into the rack.. managed to dislodge an external SCSI cable, of a server, of which the screws were not tighted
(lesson learnt here: tighten all screws for cables, especially for critical ones like the SCSI cable). We did not realise the SCSI cable
was dislodged. First sign of trouble was the fault light turned on for 1 drive out of 6 for a SCSI array, configured to RAID 10.
Okay, that's not too bad.. just a drive failure right? okay, let's just replace the faulty SCSI hard disk.. pull out faulty disk,
insert new disk. fault light changed status, and the disk starts syncing, or so I thought. Then.. the fault lights for 4 out of the
6 drives turned on. Ouch. 4 drives out of 6 is good enough for data loss even for RAID 10. Restarted the server, and accessed the
RAID card menu.. pulled out 3 of the drives marked faulty, and replaced them, tried marking the remaining faulty as good, i.e. 1 drive
out of each RAID 1, of the RAID 10 will be marked as good, RAID array will be ok. The RAID card could not detect some of the drives.
getting worse and worse.. Checked the SCSI cable.. aha.. its dislodged.. pushed the cable in, tightened the screws.. marked 3 of the
drives out of 6 as good.. worked! resynced the other 3 drives as well.
Xssist
Nov 08
|
|
[Security] Destruction of faulty hard disks |
[ More ] |
Over time, we have accumulated a number of hard disks that are faulty. Fortunately, most of these come from servers with RAID 1,
so there wasn't data lost, or server downtime. However, there is customer data on the disks, so we hang on to the disks,
rather than discard or return for warranty exchange, until we figure out how to destroy the data on the disks.
Recently, we looked at how to destroy these hard disks. There's degaussing, shredding the entire harddisk, purpose made machines to drill
holes through the platters etc. Lots of videos on youtube of demos of products for destroying hard disks. The harddisk shredder was particularly
entertaining.
We have only thereabouts 30 disks that needs to be destroyed, so getting equipment that costs SGD 15000 and up is a bit hard to justify. It was
tempting though. In any case, we went the "labour intensive" route of taking apart the disks by unscrewing the hard disk casing,
and putting the PCB and platters through a shredder. Why destroy the PCB as well? Because there's a cache chip on it which contains data.
Here's some photos of a disk being dissected,
  
 
Xssist
Mar 09
|
|
[Sysadmin] BIOS upgrades - uniflash - hotflash |
[ More ] |
We were updating BIOS for servers, and ran into problems with a few of them. The flash chip
on several of the servers were faulty; they were okay if left alone, and used for read only when server is starting up,
but attempt to flash new firmware on the chip, and the data gets corrupted. Essentially, several of the servers
were bricked, since the BIOS was corrupted.
To fix the bricked servers, we had to find replacement BIOS chip, reflash, and install into the bricked servers.
The faulty part was SST49LF040-33-4C-NH, 128x4K (512K). I looked around but the closest I could find was
SST49LF080A 33-4C-NHE which turned out to be 256x4K (1MB). i.e. double in size. Bought 20 pcs of those.
To flash the chip, I had to do what is known as hot flashing. Which is to get a similar server
with working BIOS, power up the server, remove the BIOS chip with the server running, put in a new chip, and flash.
The BIOS flashing software refused to write to the 1MB chip as the firmware is 512KB. Fortunately, a 3rd party software known as
uniflash was able to "pretend" the chip is SST49LF040-33-4C-NH, and write to it. The verify went ok, and after installing
the new chips into the bricked servers, the servers booted up fine.
Mar 2010
|
|
[Storage] Benchmark using iometer on linux |
[ More ] |
There are plenty of software for testing harddisk performance. However, the focus is mainly on read and write performance, and are usually
targeted at desktop users. For web, mail and database servers, the requirement is for high random read write IOPs rather than sequential read
or sequential write.
On that basis, iometer is one of the few tools suitable for benchmarking a harddisk for use on a server. Using iometer on windows is straight
forward, but on linux, there are a few obstacles to go through.
Following are my observations, and steps to follow in using iometer on linux; on a fresh CentOS installation. I am particularly interested in
testing the Intel X25-E
and X25-M SSDs on iometer.
Intel quotes 4KB results based on "8 GB span", and "up to"; which does not gives a picture of what the sustained IOPs are.
I am exploring using those SSDs in servers, particularly for VPS servers, so finding out the performance of the
Intel SSDs vs SCSI is important for Xssist.
In various versions, eg. 2006 version, iometer uses O_DIRECT. Yet, on others, the O_DIRECT option is missing. It appears use of O_DIRECT will
not allow queue depth more than 1 per dynamo process. It is possible to set queue depth in the iometer GUI, but the actual run will be limited to
queue depth 1; your mileage may vary, confirm the queue depth with iostat.
The latest available iometer on sourceforge, iometer-2008-06-22-rc2.src.tgz, does not use O_DIRECT, grep of the source code
does not show usage of O_DIRECT.
However, without O_DIRECT, I could not get dynamo to produce write IOPS while doing random 4KB RW tests, there is read IOPS but very minimal write
IOPS, when monitored using iostat.
What I do to work around the problem is to use the source with O_DIRECT, and open multiple dynamo processes to generate higher queue depth.
Steps for using iometer,
- to download source from http://sourceforge.net/projects/iometer/
- rename the Makefile with suitable extension to makefile
eg. mv Makefile-Linux.x86_64 makefile
- make dynamo
- disable iptables
- download windows version to a pc. run iometer on the pc
- run dynamo on the linux server
[root@bench src]# ./dynamo -i 192.168.1.7 -m 192.168.1.2
where 192.168.1.7 is the IP of the pc running iometer. 192.168.1.2 is IP of the server running dynamo
If all goes well, you will see the following,
example of output from dynamo of a correct startup
[root@bench src]# ./dynamo -i 192.168.1.7 -m 192.168.1.2
Fail to open kstat device file. You can ignore this warning unless you are running dynamo on XSCALE CPU.
Command line parameter(s):
Looking for Iometer on "192.168.1.7"
Sending login request...
bench.xssist.com
192.168.1.2 (port 33839)
Successful PortTCP::Connect
- port name: 192.168.1.7
*** If dynamo and iometer hangs here, please make sure
*** you use a correct -m <manager_computer_name> that
*** can ping from iometer machine. use IP if need.
Login accepted.
Reporting drive information...
Set_Sizes: Open on "/sys/iobw.tst" failed (error Permission denied).
Set_Sizes: Open on "/dev/shm/iobw.tst" failed (error Invalid argument).
Set_Sizes: Open on "/proc/sys/fs/binfmt_misc/iobw.tst" failed (error Permission denied).
Set_Sizes: Open on "/var/lib/nfs/rpc_pipefs/iobw.tst" failed (error Permission denied).
Physical drives (raw devices)...
Reporting TCP network information...
done.
Mar 2010
|
|
[Sysadmin] Sizing for Virtual Private Server (VPS) & SSDs |
[ More ] |
Hardware requirements for VPS is pretty interesting; in the sense of a problem to be solved. CPU performance has improved significantly year
after year, to the extend that 10 x 5-year old servers, which used to cost $5000 each, can be converted to 10 VPS, and placed into 1 physical server,
which cost $5000, and can perform well... if CPU is all that matters.
Unfortunately, the 5-year old server with a U160 10K SCSI, compared to the new server with 15K SCSI is not very far off in disk IOPs performance.
Disk IOPs is the bottleneck in many servers, rather than CPUs. In sizing a server for hosting multiple VPS, we need to put in as much RAM as
possible, to allow the OS to use the RAM for cache, and avoid reads where possible.
Next, choose storage with high random RW IOPs. eg. RAID 10, 15K drives. And possibly SSDs if the performance justifies the price. Intel quotes
very high 4KB IOPs for the X25-E and X25-M. Very tempting. Unfortunately, the details of tests done are not available with the spec sheets. Stating
"8GB span" and "up to" in the spec sheet is not all that reassuing. Performance is also known to vary significantly during benchmarking tests,
depending on how much of the SSDs is used, and length of test runs.
I have several pieces of the X25-M and X25-E, and will be testing the SSDs. If they produce at least 3 times more IOPs, sustained, compared to
15K drives, they are going into our next generation of VPS servers.
Mar 2010
|
|
[Sysadmin] iphone, ipod - bluetooth keyboard - Nokia e51 |
[ More ] |
I was using a Nokia 9300i for the past 3 years, mainly for its qwerty keyboard, for emergencies where I'm out of office, and without a laptop
with Internet access. The 9300i has worked well, but the hardware was failing, screen blanking out occasionally etc. I do not want phones with
cameras, so the successors to the 9300i was out. All came with cameras. The non camera phones either do not have qwerty keyboards or they have
small screens. Its pretty hard to find a good device without camera.
I also got a Nokia e51, and looked for a bluetooth keyboard. There were a few, but reviews were mainly poor, mostly due to durability issues. I
settled on the apple bluetooth keyboard. The e51 I got came with an application installed, called "wl. keybd.", "Menu->Office->Wl. keybd."
which does detect the apple keyboard. PuTTY is available for the e51, so with PuTTY and with the bluetooth keyboard, I had a replacement for the
Nokia 9300i, for an emergency ssh device. The left command key on the keyboard works as the left blue key on the nokia, and the right command key works
as the right blue key on the nokia. i.e. using the command keys on the apple keyboard allows selection of "Menu, Notes, Options, Exit" etc. It is
also possible to unlock the keypad using the left command key, and shift-8. Pressing the left command key followed by the right option key
works to unlock the keypad as well. I have not found a way to lock the phone keypad again though. Cursor keys work as well, and esc can be used
to exit menus.
I tried for a while to use the Nokia 7700. Its a Internet tablet without camera. It has a "large" screen, and has wifi. It was difficult to pair
with a bluetooth keyboard but I did eventually got it to work with the apple wireless keyboard, except that the "enter" key does not send the
correct keys in a shell session, and I didn't have time to look further.
Later on, when I read about the ipod touch 3rd gen, I thought it would be the ideal device for ssh sessions. It has a "large" screen, it has
bluetooth, its from apple; it must support the apple wireless keyboard right?? I bought a ipod 64GB right away, and I was very wrong.
Unfortunately, apple does not provide a bluetooth stack for iphone/ ipod for use with a keyboard! Searching on the Internet showed a guy Ralf
Ackermann, who managed to get the apple keyboard to work with a iphone. I wasn't up to duplicating his work though.
I made do with the touch screen keyboard for a few months. Got a pleasant surprise recently when I checked for a keyboard for iphone again; There's
a app available to allow bluetooth keyboards to collect to the iphone/ ipod. It is in the Cydia store, "BTstack Keyboard", by Matthias Ringwald,
for USD 5. Bought it right away. Now the ipod works as I thought it should, with the apple wireless keyboard. Cursor keys does work in notes,
but not in mobile terminal or iSSH.
Mar 2010
Update: In Apr 2010, Apple showed its OS 4 for the iPhone. It will be available for iPhone and iPod touch between June to August 2010,
and appears to allow bluetooth keyboards to work with the iPhone and iPod touch.
Additional Updates (30th June 2010): iOS 4 has been available for about a week. Bluetooth pairing with keyboard is available under "Settings" ->
General -> Bluetooth
I tested with a Apple wireless keyboard, aluminium (model number:A1255). Pairing goes well. The cursor keys works in "Notes". Volume, Play/ Pause
and brightness keys work as well. Unfortunately, no navigation available via the keyboard (old model with 3 batteries), eg. Home button, selecting
apps to open are not available via keyboard. Caps Lock and caps lock light does work. Eject button pops up on screen keyboard. Shift allows selection
of text, in "Notes", as well as copy and paste via Command-C, Command-V. Command-X does cut as well.
Cursor keys not working in iSSH as of 30th Jun 2010. iSSH does have a method to input cursors during the touchscreen but its far inferior to an
actual physical keyboard.
|
|
[SSD] Benchmark Intel X25-E and Intel X25-M flash SSDs |
[ More ] |
Benchmarking flash SSDs (solid state disks) is significantly more difficult than benchmarking the conventional spinning disk, as the SSD
performance changes, often signficantly, while data is read and written to the SSD. Not performance changes over a timefram of months, but minute by
minute. It may be due to wear levelling and internal log-structured file systems. In any case, extra care has to be taken when benchmarking SSDs.
Each test needs to be long enough to expose the worst case performance of the SSD, and each test need to be performed after a ATA security erase, to
ensure the SSD starts the test with a clean slate. It is also necessary to fill up the SSD to test how it performs as the SSD free space gets used
up.
For many applications, peak performance for an initial few seconds from the SSD is not meaningful. If the SSD can provide 10,000 IOPs for an
initial 2 seconds, but thereafter, for the rest of its life span without a ATA security erase, slow down sharply to 1200 IOPs; and waver up and down,
with an average of 2400 IOPs within an hour time span, the SSD may only be suitable for a server that needs at least 1200 IOPs.
Realtime applications like web, email, database may need to be sized to the worst case IOPs. On the other hand, servers that does batch jobs which
do not need interactions with users, and do not need consistent run times, may be more tolerant of inconsistent performance, including sharp drops in
IOPs, as long as the average IOPs figures are high.
In the followup posts, I will post results of benchmarking attempts for the
Intel X25-E and
Intel X25-M SSDs; with focus on finding a
configuration that provides stable 4K random 70/30 RW IOPs at a low queue depth, and is suitable for linux server (web, mail, database) usage.
IOmeter will be used as the benchmarking tool. It is time consuming, each run taking several hours, and I expect to continue testing configurations
for using SSDs in servers requiring high IOPs and low latencies.
Lim Wee Cheong
21st March 2010
|
|
[SSD] Intel X25-E 64GB G1, 4KB Random IOPS, iometer benchmark |
[ More ] |
Iometer is used in the following benchmark runs on the Intel X25-E, 64GB G1 SSD. 2 tests were done, 1 with write cache, 1 without write
cache.
The tests ran for over 12 hours each. In the following graphs, only 32000 seconds (8+ hrs) is shown, due to limitation of the software
used to generate the graph.
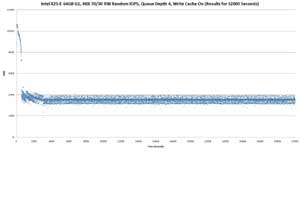
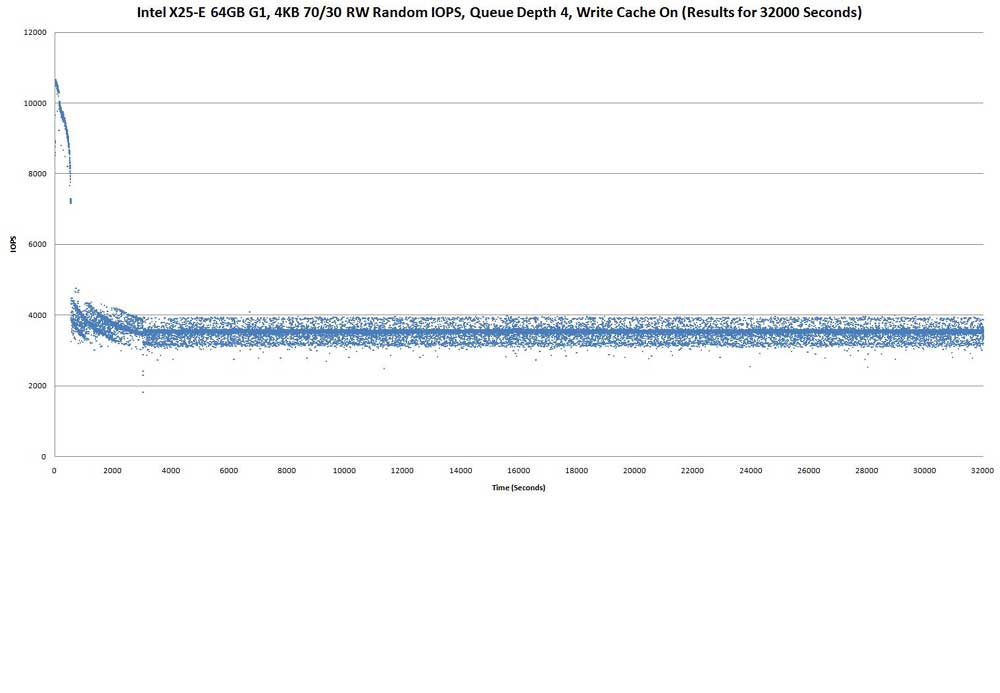
Above scatter graph shows the IOPS over 32000 seconds (8+ hours)for the X25-E 64GB G1, with write cache enabled. The test starts off at
8915 IOPS, hit a high of 10665 IOPS at the 15th second, and thereafter declined, with a sharp drop from 7228 IOPS at the 544th second to 4327
IOPS in the next second. Thereafter, the IOPs gradually decreased till 3032nd second, where there's a drop to 2874, then 2295, and finally
1828 IOPS, before recovering.
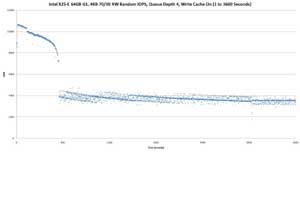
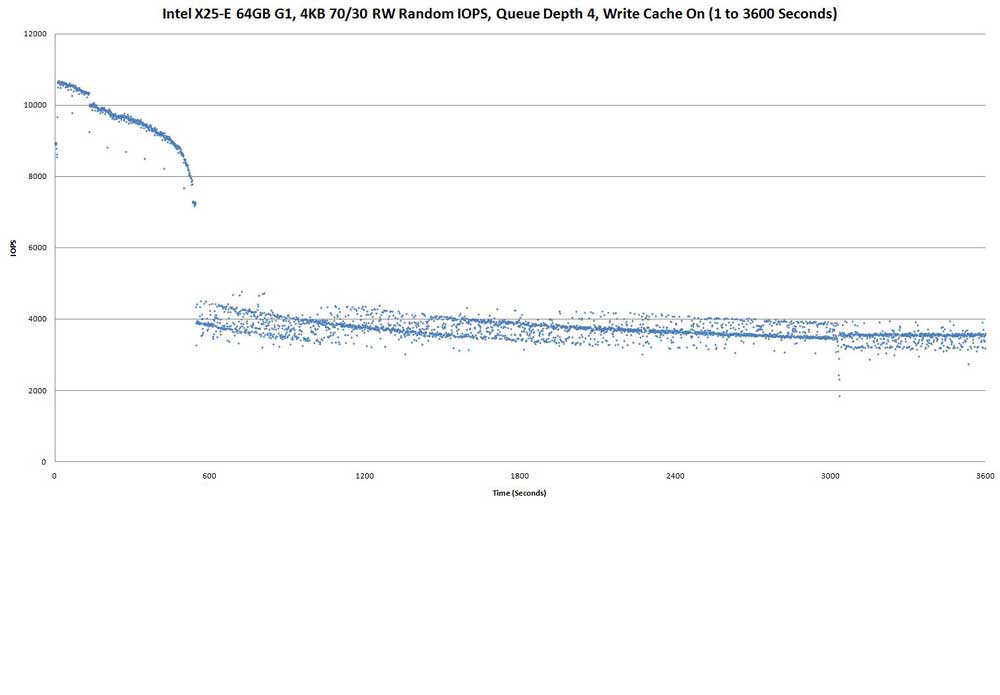
Above graph shows same run, but results for 1st 3600 seconds.
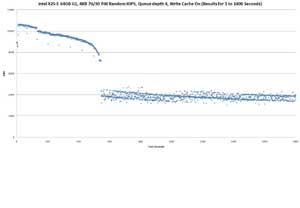
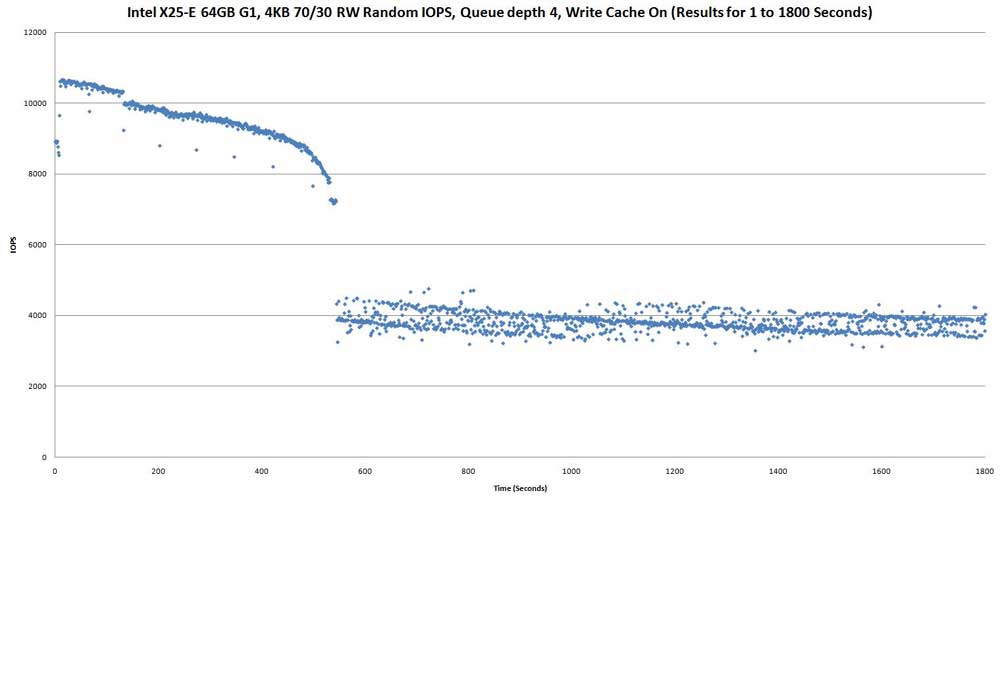
Above graph shows same run, but results for 1st 1800 seconds.
Following graphs show results for the same SSD, with write cache disabled, using hdparm -W 0 /dev/sdb and verified using hdparm -I
/dev/sdb
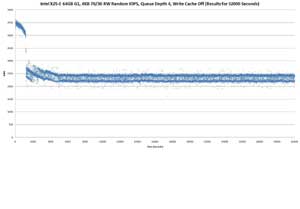
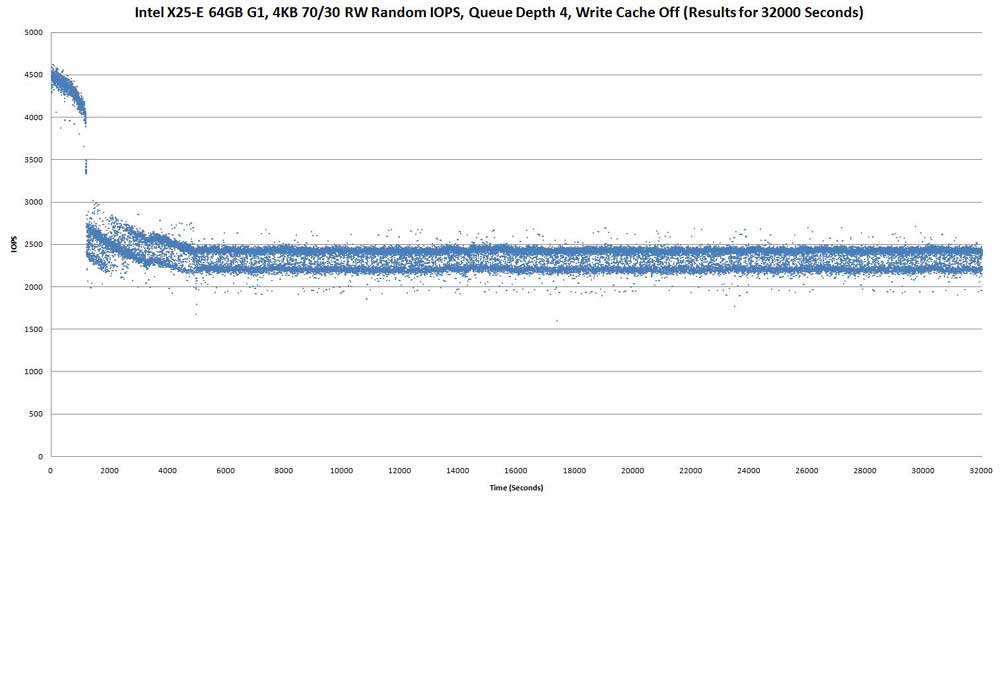
Above: Intel X25-E 64GB G1, 4KB 70/30 RW Random IOPS, Queue Depth 4, Write Cache Off (Results for 32000 Seconds)
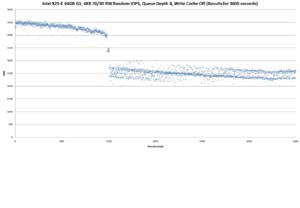
Above: Intel X25-E 64GB G1, 4KB 70/30 RW Random IOPS, Queue Depth 4, Write Cache Off (Results for 3600 Seconds)
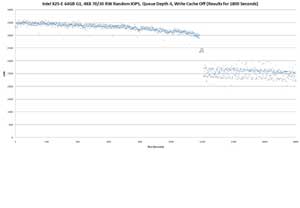
Above: Intel X25-E 64GB G1, 4KB 70/30 RW Random IOPS, Queue Depth 4, Write Cache Off (Results for 1800 Seconds)
27 Mar 2010
|
|
[Sysadmin] e2label, fdisk, /etc/fstab, mount, linux rescue, rescue disk, CentOS |
[ More ] |
Let's run through an example of a fresh disk, that needs to be configured, going through partitioning with fdisk, make filesystem, filesystem
labelled using e2label, /etc/fstab edited, and mounted using mount. This is relevent for CentOS 3.x, 4.x 5.x; YMMV for other flavours.
First, a run through of each command, with usage examples.
fdisk
if the partitioning of the drive is unknown, fdisk -l can be used to list the partition table of the drive. eg. fdisk -l /dev/sdb
following is an example of a disk without a partition table
# fdisk -l /dev/sdb
Disk /dev/sdb: 74.3 GB, 74355769344 bytes
255 heads, 63 sectors/track, 9039 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Disk /dev/sdb doesn't contain a valid partition table
and here's an example of a disk with valid partition table
# fdisk -l /dev/sda
Disk /dev/sda: 299.9 GB, 299974524928 bytes
255 heads, 63 sectors/track, 36469 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
| Device |
Boot |
Start |
End |
Blocks |
Id |
System |
| /dev/sda1 | * | 1 | 13 | 104391 | 83 | Linux |
| /dev/sda2 | | 14 | 268 | 2048287+ | 82 | Linux swap |
| /dev/sda3 | | 269 | 36469 | 290784532+ | 83 | Linux |
to change the partitions on a drive without partition table, such as a new drive, use fdisk
eg. fdisk /dev/sdb
# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel. Changes will remain in memory only,
until you decide to write them. After that, of course, the previous
content won't be recoverable.
The number of cylinders for this disk is set to 9039.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
1) software that runs at boot time (e.g., old versions of LILO)
2) booting and partitioning software from other OSs
(e.g., DOS FDISK, OS/2 FDISK)
Command (m for help):
m will list the options available.
eg. p will print the partition table, n is for adding new partition table;
and after the changes are done, w will commit the changes, and exit the program.
e2label
Usage of e2label is simple. manpage for e2label shows following command line options,
e2label device [ new-label ]
device can be the entire drive or a partition.
eg.
/dev/sda is the entire drive
/dev/sda1 is the first partition of device /dev/sda
/dev/sda2 is the second partition of device /dev/sda
eg. to show the label of /dev/sda1 and /dev/sda3
# e2label /dev/sda1
/boot
# e2label /dev/sda3
/
To change the label for /dev/sda3, do as follows,
# e2label /dev/sda3 changed-label
and to confirm the change was done sucessfully,
# e2label /dev/sda3
changed-label
if you want a / in front of the label,
# e2label /dev/sda3 /changed-label
to verify that the change was done,
# e2label /dev/sda3
/changed-label
if you want the server to be able to boot next time round, ensure changes are made to /etc/fstab as well. Otherwise, on the next boot, you may be
prompted with errors, eg.
fsck.ext3: Unable to resolve 'LABEL=/boot'
fsck.ext3: Unable to resolve 'LABEL=/'
in which case, you can boot up with a rescue disk, eg. CentOS installation disk, enter "linux rescue" at prompt; chroot /mnt/sysimage and edit
/etc/fstab accordingly. Alternatively, if you are prompted for root password, and gets a shell, you may be able to edit /etc/fstab. If the
filesystem is readonly, remount the filesytem readwrite. eg. mount -o remount,rw /
mount, umount
# mount /dev/sdb5 /tmp/mnt
will mount /dev/sdb5 on the /tmp/mnt directory
if /tmp/mnt does not exist, it needs to be created, using mkdir
to unmount the device, use umount /dev/sdb5 or umount /tmp/mnt
Example of partitioning, formatting and labelling of a new drive
2 partitions to be created
100MB and rest of the drive
# fdisk /dev/sdb
Device contains neither a valid DOS partition table, nor Sun, SGI or OSF disklabel
Building a new DOS disklabel. Changes will remain in memory only,
until you decide to write them. After that, of course, the previous content won't be recoverable.
The number of cylinders for this disk is set to 9039.
There is nothing wrong with that, but this is larger than 1024,
and could in certain setups cause problems with:
1) software that runs at boot time (e.g., old versions of LILO)
2) booting and partitioning software from other OSs
(e.g., DOS FDISK, OS/2 FDISK)
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-9039, default 1):
Using default value 1
Last cylinder or +size or +sizeM or +sizeK (1-9039, default 9039): +100M
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 2
First cylinder (14-9039, default 14):
Using default value 14
Last cylinder or +size or +sizeM or +sizeK (14-9039, default 9039):
Using default value 9039
Command (m for help): p
Disk /dev/sdb: 74.3 GB, 74355769344 bytes
255 heads, 63 sectors/track, 9039 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
| Device |
Boot |
Start |
End |
Blocks |
Id |
System |
| /dev/sda1 | | 1 | 13 | 104391 | 83 | Linux |
| /dev/sda2 | | 14 | 9039 | 72501345 | 83 | Linux |
Command (m for help): w
The partition table has been altered!
Calling ioctl() to re-read partition table.
Syncing disks.
Next: format both partitions as ext3 filesystems
# mkfs.ext3 /dev/sdb1
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=1024 (log=0)
Fragment size=1024 (log=0)
26104 inodes, 104388 blocks
5219 blocks (5.00%) reserved for the super user
First data block=1
Maximum filesystem blocks=67371008
13 block groups
8192 blocks per group, 8192 fragments per group
2008 inodes per group
Superblock backups stored on blocks:
8193, 24577, 40961, 57345, 73729
Writing inode tables: done
Creating journal (4096 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 22 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
# mkfs.ext3 /dev/sdb2
mke2fs 1.39 (29-May-2006)
Filesystem label=
OS type: Linux
Block size=4096 (log=2)
Fragment size=4096 (log=2)
9076736 inodes, 18125336 blocks
906266 blocks (5.00%) reserved for the super user
First data block=0
Maximum filesystem blocks=4294967296
554 block groups
32768 blocks per group, 32768 fragments per group
16384 inodes per group
Superblock backups stored on blocks:
32768, 98304, 163840, 229376, 294912, 819200, 884736, 1605632, 2654208, 4096000, 7962624, 11239424
Writing inode tables: done
Creating journal (32768 blocks): done
Writing superblocks and filesystem accounting information: done
This filesystem will be automatically checked every 33 mounts or
180 days, whichever comes first. Use tune2fs -c or -i to override.
next: use e2label to label the volumes. Although both mkfs3.ext and
tune2fs is capable of labelling, with the -L option, I am deliberately
using e2label in this example to demonstrate the use of e2label.
# e2label /dev/sdb1 /drive2-100MB
confirm its done.
# e2label /dev/sdb1
/drive2-100MB
label sdb2 next,
# e2label /dev/sdb2 /drive2-restofdrive
Warning: label too long, truncating.
# e2label /dev/sdb2
/drive2-restofdr
the description used was too long, and got truncated. maximum for label is 16 characters.
next, we try to mount and unmount the 2 filesystems created,
mount shows what has already been mounted. in addition, the -l option shows the filesystem label
# mount -l
/dev/sda3 on / type ext3 (rw) [/]
proc on /proc type proc (rw)
sysfs on /sys type sysfs (rw)
devpts on /dev/pts type devpts (rw,gid=5,mode=620)
/dev/sda1 on /boot type ext3 (rw) [/boot]
tmpfs on /dev/shm type tmpfs (rw)
none on /proc/sys/fs/binfmt_misc type binfmt_misc (rw)
sunrpc on /var/lib/nfs/rpc_pipefs type rpc_pipefs (rw)
We are mainly concerned with the drives, so let's grep for the relevent entries
#mount -l | grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
We need mount points; the following mount points are created,
# mkdir /mountpt1
# mkdir /mountpt2
to manually mount the drives,
# mount /dev/sdb1 /mountpt1
check that it is mounted,
# mount -l|grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
/dev/sdb1 on /mountpt1 type ext3 (rw) [/drive2-100MB]
# mount /dev/sdb2 /mountpt2
# mount -l|grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
/dev/sdb1 on /mountpt1 type ext3 (rw) [/drive2-100MB]
/dev/sdb2 on /mountpt2 type ext3 (rw) [/drive2-restofdr]
to unmount, use umount
# umount /dev/sdb1
# umount /dev/sdb2
# mount -l|grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
we can also mount the filesystems using the filesystem labels,
# mount -L /drive2-100MB /mountpt1/
# mount -L /drive2-restofdr /mountpt2/
# mount -l |grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
/dev/sdb1 on /mountpt1 type ext3 (rw) [/drive2-100MB]
/dev/sdb2 on /mountpt2 type ext3 (rw) [/drive2-restofdr]
unmount can also use the mount point instead of the device, eg.
# umount /mountpt1
# umount /mountpt2
# mount -l |grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
next: edit /etc/fstab, add in entries for the new drive if we want it to be mounted at boot up.
following is existing /etc/fstab for the server, which was installed for purpose of this tutorial,
| LABEL=/ | / | ext3 | defaults | 1 | 1 |
| LABEL=/boot | /boot | ext3 | defaults | 1 | 2 |
| tmpfs | /dev/shm | tmpfs | defaults | 0 | 0 |
| devpts | /dev/pts | devpts | gid=5,mode=620 | 0 | 0 |
| sysfs | /sys | sysfs | defaults | 0 | 0 |
| proc | /proc | proc | defaults | 0 | 0 |
| LABEL=SWAP-sda2 | swap | swap | defaults | 0 | 0 |
add the following entries,
| LABEL=/drive2-100MB | /mountpt1 | ext3 | defaults | 1 | 1 |
| LABEL=/drive2-restofdr | /mountpt2 | ext3 | defaults | 1 | 2 |
mount has a -a option which reads /etc/fstab and mounts all filesystems mentioned in the file,
# mount -a
# mount -l |grep /dev/sd
/dev/sda3 on / type ext3 (rw) [/]
/dev/sda1 on /boot type ext3 (rw) [/boot]
/dev/sdb1 on /mountpt1 type ext3 (rw) [/drive2-100MB]
/dev/sdb2 on /mountpt2 type ext3 (rw) [/drive2-restofdr]
next, reboot, and ensure the new drive is mounted automatically, and accessible via the mount points, /mountpt1, /mountpt2
1 Apr 2010
|
|
[SSD] Intel X25-M 160GB G2, 4KB Random IOPS, iometer benchmark |
[ More ] |
Iometer is used in the following benchmark runs on the Intel X25-M, 160GB G2 SSD. 2 tests were done, 1 with write cache, 1 without write
cache. Following graphs show the results. OS is Centos 5.4 64 bit, the controller is nForce Pro 2200/2050 on the motherboard. When comparing
the graphs, please note the test with cache on ran for 21000s, and test with cache off ran for 32000s.
With the write cache on, the results for first few minutes were above 9,000 IOPS, but nosedived thereafter. There are benchmarks done by
consumer hardware sites that indicates the write IOPS of the X25-M G2 is comparable or better than
X25-E G1.
However, with the extend test runs that we did, we find the random IOPS performance of the X25-M G2 (MLC) to be far lower than the X25-E G1 (SLC).

Graph of 32000s run with 4KB 70/30 RW Random IOPS, queue depth 4, write cache off

Graph of 21000s run with 4KB 70/30 RW Random IOPS, queue depth 4, write cache on
13 Apr 2010
|
|
[cPanel] ClamAV version has reached End of Life! Please upgrade to version 0.95 |
[ More ] |
Several servers running cPanel had problems with incoming mails.
Emails may be rejected by the server with the response '451 Temporary local problem - please try later'
Restarting exim shows a link to clamav
# /etc/init.d/exim restart
Shutting down clamd: [FAILED]
Shutting down exim: [ OK ]
Shutting down spamd: [ OK ]
Starting clamd: LibClamAV Warning:
***********************************************************
LibClamAV Warning: *** This version of the ClamAV engine is outdated.
***
LibClamAV Warning: *** DON'T PANIC! Read http://www.clamav.net/support/faq
***
LibClamAV Warning:
***********************************************************
LibClamAV Error: cli_hex2str(): Malformed hexstring: This ClamAV version
has reached End of Life! Please upgrade to version 0.95 or later. For more
information see www.clamav.net/eol-clamav-094 and www.clamav.net/download
(length: 169)
LibClamAV Error: Problem parsing database at line 742
LibClamAV Error: Can't load daily.ndb: Malformed database
LibClamAV Error: cli_tgzload: Can't load daily.ndb
LibClamAV Error: Can't load /usr/share/clamav/daily.cld: Malformed
database
ERROR: Malformed database
[FAILED]
Starting exim: [ OK ]
Starting exim-smtps: [ OK ]
If clamav is checked, click on save. Clamav will be updated to
clamav-0.95.3 or version listed as latest version in "Manage Plugins".

If clamav is not checked, you may have installed clamav manually. In that case, you can either update clamav manually, or uninstall it and use
cPanel to install clamav for you.
Lim Wee Cheong
16th Apr 2010
|
|
[SSD] Comparison of Intel X25-E G1 vs Intel X25-M G2 |
[ More ] |
We are looking for SSDs to replace SCSI disks. IOPS is the main deciding factor for which SSD to use. The best SSD as shown in
consumer review sites are those from Intel. Unfortunately, there are no IOPS comparisons for the Intel X25-E vs the X25-M that are done
over several hours. Most consumer reviews uses software that runs for short periods of seconds or minutes. These tests are inadequate as
they are too short, and do not show the varying performance of SSDs when under sustained load over long periods. Several reviews end up
stating the X25-M G2 (MLC) as on par or better than the X25-E G1 (SLC). We wanted to confirm the X25-M G2 performance, using iometer;
in particular we wanted to see high, sustained, 4K random IOPS for the X25-M G2, that is comparable to the X25-E G1. Unfortunately, our tests
show the X25-E G1 having around 3 times higher IOPS compared to the X25-M G2 when the tests run for several hours. Following is a graph
comparing the X25-E G1 64GB vs the X25-M G2 160GB. The X25-M G2 starts off with IOPS over 10K, slightly higher than the X25-E G1. The
IOPS of the X25-M G2 drop rapidly thereafter. Although the X25-M G2 still has high IOPS compared to single spinning disks, the performance
is clearly inferior to the X25-E G1.

Intel X25-E G1 vs Intel X25-M G2, iometer 4K Random IOPS
May 2010
|
|
[Sysadmin] opensuse, fix waiting for mandatory device, eth0, eth1, eth2, eth3 |
[ More ] |
You have faulty hardware in a PC or server, and moved the harddisks to another chassis. The OS boots up, however, when initializing the network,
opensuse cannot find the original network card, and comes up with the error "...waiting for mandatory device...".
It also discovers additional network devices, eg. eth2, eth3, while not finding the original ones, eg. eth0 and eth1. This is because the MAC
addresses are different.
To fix this, cd to the /etc/udev/rules.d directory
grep for the network interface that is missing, eg. grep eth0 *
You may find 70-persistent-net.rules has matching entries
The file will contain entries similar to following,
# PCI device 0x14e4:0x1640 (tg3)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*",
ATTR{address}=="00:30:40:75:dc:82", ATTR{type=="1",KERNEL=="eth*",
NAME="eth1"
# PCI device 0x14e4:0x1640 (tg3)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*",
ATTR{address}=="00:30:40:75:dc:83", ATTR{type=="1",KERNEL=="eth*",
NAME="eth0"
# PCI device 0x14e4:0x1640 (tg3)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*",
ATTR{address}=="00:30:40:75:dc:08", ATTR{type=="1",KERNEL=="eth*",
NAME="eth2"
# PCI device 0x14e4:0x1640 (tg3)
SUBSYSTEM=="net", ACTION=="add", DRIVERS=="?*",
ATTR{address}=="00:30:40:75:dc:09", ATTR{type=="1",KERNEL=="eth*",
NAME="eth3"
In the above example, eth2 and eth3 are new, i.e. they contain the MAC addresses of the NIC in the replacement hardware. The entries for eth0 and
eth1 are the MAC of the NIC in the faulty hardware. To fix, remove the entries for eth0 and eth1, and change eth2 to eth0 and eth3 to eth1
respectively. Before editing, you may want to make a copy of the file in case of mistakes. Remember to keep each entry as an entire line without
linefeeds breaking them up, as may happen for editors like nano.
15 Jun 2010
|
|
[cPanel] How to install Java, ImageMagick and ffmpeg |
[ More ] |
1. Install Java
Use cPanel to do the installation, and manage java.
Within WHM, go to "EasyApache (Apache Update)".
Use your existing defaults, and select "tomcat"; and allow cPanel to recompile apache and php. Java will also be installed.
2. If you do not need Tomcat, it can, and should be disabled.
Within WHM, go to service manager -> disable tomcat.
3. Install ImageMagick
login to shell, and run the following script,
/scripts/installimagemagick
The script from cPanel will install ImageMagick
4. Setup dag repo (which will be used to install ffmpeg)
See http://dag.wieers.com/rpm/FAQ.php#B2 for the instructions
eg, if you have a CentOS 5.x 64 bit server, use the following,
rpm -Uhv
http://apt.sw.be/redhat/el5/en/x86_64/rpmforge/RPMS//rpmforge-release-0.3.6-1.el5.rf.x86_64.rpm
5. Install ffmpeg
within shell, run following,
yum install ffmpeg
Xssist
28 Jun 2010
|
|
[Perl] Opening text files for reading, and simple regexp (regular expressions) |
[ More ] |
Perl is easy to use, and pretty good for working on text files.
If you have a text file named records.txt with the following,
Name,Class,Subject,Score
Alvin,1A1,Maths,80
Alvin,1A1,Science,92
Alvin,1A1,English,85
Roy,1A1,Maths,80
Roy,1A1,Science,92
Roy,1A1,English,92
Susan,1A2,Maths,85
Susan,1A2,Science,85
Susan,1A2,English,85
Following is an example for opening the file for reading, and printing out all lines in the file.
----- begin example -------
#!/usr/bin/perl
open FILE, "records.txt";
while ($line=<FILE>){
print $line;
}
----- end example -------
Instead of FILE, you can use FILEIN, MYFILE, or STUDENT etc.
What if you want the filename to be specified at runtime, instead of hardcoded in the script?
use shift, as shown in the following example,
----- begin example -------
#!/usr/bin/perl
$filename=shift;
open STUDENT, $filename or die "error opening $filename\n";
while ($line=<STUDENT>){
print $line;
}
----- end example -------
if the script is named example.pl, it can be executed as follows, ./example.pl records.txt
In the example above, I also sneaked in the use of "die"; If the open fails, print out a error message, and end the script.
The use of "or" is similar to following
if (! (open STUDENT, $filename) ){
die "error opening $filename\n";
}
i.e. if whatever happens on the left of "or" does not return 1, evaluate whatever is on the right hand side of "or".
In case you are not familar with \n, it is a linefeed.
regexp
-----
To search for a string, eg. "Science", you can read in each line, and use pattern matching. Following code opens file records.txt, reads in each
line, check for "Science", and prints out the line if it matches.
----- begin example -------
#!/usr/bin/perl
open FILE, "records.txt";
while ($line=<FILE>){
if ($line=~/Science/){
print $line;
}
}
----- end example -------
How about printing out each line, split into Name, class, subject, score?
We know the format of the file, each line contains name, class, subject and score, delimited by ",". A regexp of ^(.*?),(.*?),(.*?),(.*?)$ will
allow us to extract 4 variables from the line.
^ matches beginning of line
(.*?), matches one or more characters till ",", and assigns the matched string into a variable
$ matches end of line
----- begin example -------
#!/usr/bin/perl
open FILE, "records.txt";
while ($line=<FILE>){
if ($line=~/^(.*?),(.*?),(.*?),(.*?)$/){
print "Name:$1 Class:$2 Subject:$3 Score:$4\n";
}
}
----- end example -------
Xssist
29 Jun 2010
|
|
[Sysadmin] mount: could not find filesystem '/dev/root' |
[ More ] |
We had a server that could not be powered up about a month ago. Following records the problems encountered and how they were fixed.
Server was installed with CentOS, and Virtuozzo.
To bring server up as fast as possible, we decided not to troubleshoot the individual components in the server chassis. Instead, we moved the hard
disks over to another chassis. Unfortunately, when booting up, /dev/root could not be found, as shown in following screen shot.
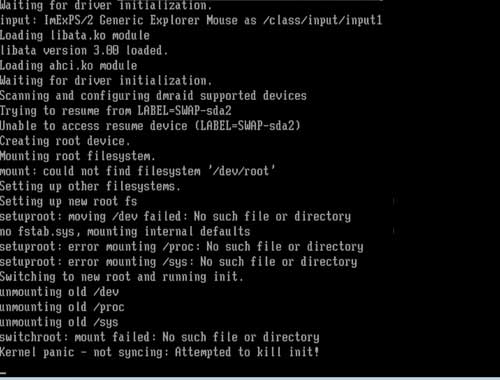
This was due to initrd.img not loading device driver for the different SCSI card in the replacement chassis.
To fix this, we booted up using a CentOS installation disk, i.e. linux rescue, brought up the network interface, and scp the initrd.img, i.e.
/boot/initrd-* from a working server with the same chassis, and rebooted.
Upon reboot, the following errors appeared, FATAL: Could not load /lib/modules/2.6.18-028stab067.4/modules.dep
To fix this, we copied the relevent files from /lib/modules/* of the same server that donated initrd.img
Server booted up okay thereafter.
Xssist
2nd July 2010
|
|
[Sysadmin] Parallels Virtuozzo Physical server to Container migration (vzp2v) |
[ More ] |
It can be intimidating for a sysadmin used to using command line, to use a graphical interface to migrate a server. Not knowing what steps will be
taken, not being able to check the outcome of each step. Just did that recently, used the Parallels Management Console to migrate a physical
server running CentOS 5.x to a VPS. I have done plenty of vzmigrate, but not vzp2v.
The process went well. From Parallels Management Console, expand the destination server running parallels, i.e. click on the + on left hand
side of hostname, right click on "Virtuozzo Containers", go to tasks, and "Migrate Physical Server to Container.. "
Enter in the IP address of origin server, root password, and choose various options. From there, Parallels Management Console, the GUI, takes
over, and copy files to the origin physical server, "Deploying the migration agent to ...." is shown on GUI.
Several virtuozzo files are transferred to the origin server. /usr/local/share/vzlinmigrate, /var/vzagent.tmp/* and executed. The
software determines which linux distribution is used. resource usage is calculated. You are then prompted to confirm the linux distribution,
answer questions on network configuration, naming of the VPS, quotas, resource restriction etc to be used for the VPS.
There is also an option to shutdown the physical server and start the VPS after migration. The option is off by default, and I did not enable it.
rsync is then used to transfer files from the origin server to the destination VPS.
After the migration is done by the GUI, I accessed the origin physical server via KVM over IP, and shutdown the network interface, and started up
the new VPS. VPS starts up ok.
There does not appear to be risk of data loss during the migration; I did not see any "destructive" operation, ymmv (your mileage may vary).
Lim Wee Cheong
20th July 2010
|
|
|